逻辑回归
引言
逻辑回归[Logistic Regression]多用于解决分类问题,二分类多分类均可。
我们将多分类看做很多个二分类即可。
定义目标函数
在上一节,我们最后提到:通过引入
因此我们可以考虑让
现在,我们有
我们知道
观察sigmoid函数的定义域以及值域,我们发现它呈这个现状
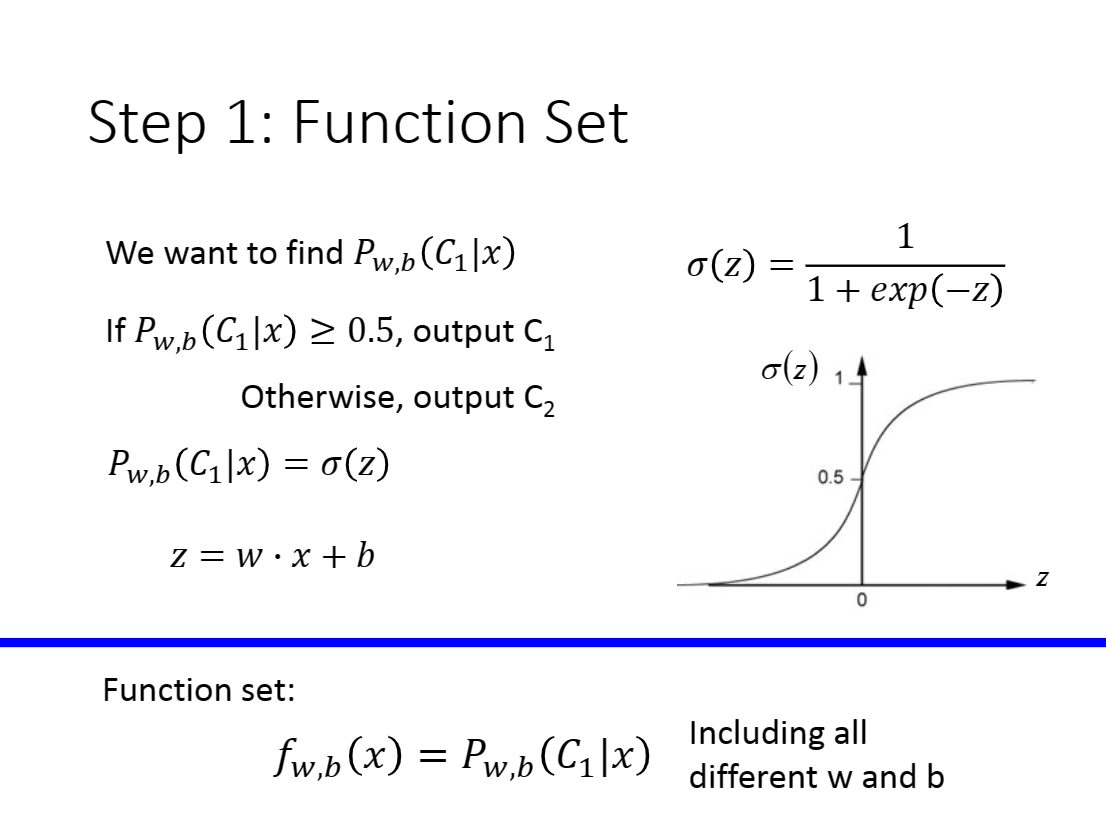
因此我们可以令
定义损失函数
损失函数要求其定义必须用数学语言表达你的目标。
我们的目标是使预测尽可能准确,即class 1要尽可能接近1,class 2要尽可能接近0。
可以知道,对于所有的
因此对于class 1,我们可以认为
对于class 2,我们可以认为
根据最大似然估计我们可以得到
$L(w,b)=P(x1)P(x_2)…*P(x{n-1})*P(x_n)$
我们想令准确率最高,即求
因为求最大值无疑是困难的,因此我们转化为求最小值



使用合适的算法求解
自然,上述式子可以容易的使用gradient descent求解。
不再赘述。

算法优化[源于ML-NLP/2.Logistics Regression.md at master · NLP-LOVE/ML-NLP (github.com)]
1 一阶方法
梯度下降、随机梯度下降、mini 随机梯度下降降法。随机梯度下降不但速度上比原始梯度下降要快,局部最优化问题时可以一定程度上抑制局部最优解的发生。
2 二阶方法:牛顿法、拟牛顿法:
这里详细说一下牛顿法的基本原理和牛顿法的应用方式。牛顿法其实就是通过切线与x轴的交点不断更新切线的位置,直到达到曲线与x轴的交点得到方程解。在实际应用中我们因为常常要求解凸优化问题,也就是要求解函数一阶导数为0的位置,而牛顿法恰好可以给这种问题提供解决方法。实际应用中牛顿法首先选择一个点作为起始点,并进行一次二阶泰勒展开得到导数为0的点进行一个更新,直到达到要求,这时牛顿法也就成了二阶求解问题,比一阶方法更快。我们常常看到的x通常为一个多维向量,这也就引出了Hessian矩阵的概念(就是x的二阶导数矩阵)。
缺点:牛顿法是定长迭代,没有步长因子,所以不能保证函数值稳定的下降,严重时甚至会失败。还有就是牛顿法要求函数一定是二阶可导的。而且计算Hessian矩阵的逆复杂度很大。
拟牛顿法: 不用二阶偏导而是构造出Hessian矩阵的近似正定对称矩阵的方法称为拟牛顿法。拟牛顿法的思路就是用一个特别的表达形式来模拟Hessian矩阵或者是他的逆使得表达式满足拟牛顿条件。主要有DFP法(逼近Hession的逆)、BFGS(直接逼近Hession矩阵)、 L-BFGS(可以减少BFGS所需的存储空间)。
格外要点[源于ML-NLP/2.Logistics Regression.md at master · NLP-LOVE/ML-NLP (github.com)]
逻辑回归为什么要对特征进行离散化。
- 非线性!非线性!非线性!逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合; 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 速度快!速度快!速度快!稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 鲁棒性!鲁棒性!鲁棒性!离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
- 方便交叉与特征组合:离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 稳定性:特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
- 简化模型:特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
逻辑回归的目标函数中增大L1正则化会是什么结果。
所有的参数w都会变成0。

快晴
スーパーヒーローになってみたい