支持向量机
(这章咕了好久
我是机器学习初学者,以下发言我不能保证其正确性,如有差错,告诉我,我会尽可能勘误。
本文涉及的数学推导多能在这里找到。
引入
支持向量机是啥
同上一节,朴素的支持向量机是一种解决线性可分的二分类机器学习算法。
至此我们可以认为支持向量机==逻辑回归,但是我们可以引入[升维]的做法,让支持向量机能够做到解决非线性可分。不过这些都是后话了。
算法做法[1]及简单数学
算法做法[1]
考虑一个可线性可分的二分类问题,显然我们用一条合适的直线就可以将两类数据分割开,因此我们考虑有最优的分割。
我们这里定义两类与划分边界的距离的最小值最大就是最优的分割。
最优分割怎么求呢,公式是什么呢
我们这里不按照直接点到直线的距离来求,这样会使公式复杂[我自己试了一下,大概是?]
对于一个二分类上任意一个点,怎么使它与划分边界的距离最短。显然,与它与划分边界垂直的点。[划分边界==超平面]

即二分类上的任意一点
我们记超平面的公式为
可以知道,
我们对这个虱子两侧同乘
根据超平面的公式,有
故化解上式,有
即任意一点与超平面的最短距离。
最后我们想构造一个超平面,使其
即如图。
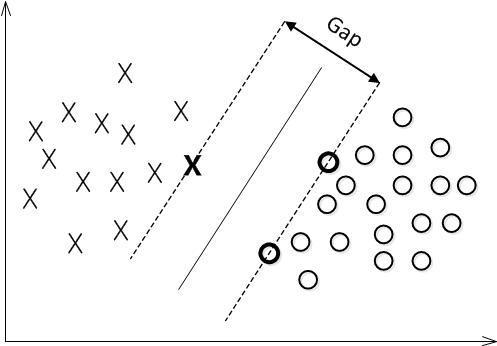
至于怎么构造,就是后话了。
为什么呢?肯定会这么想
这里先不给出严格的数学证明,我们直觉的想,如果一条直线能够划分两类,如果它与距离最近的点距离最大,就意味着它有更大的容错空间,它会更少的犯错,当然也会更少的正确。
算法做法[2]
Ⅰ.拉格朗日乘子法
承接上文,我们想构造一个最优的超平面,并且有
现在我们想定义一个损失函数,引导我们找到一个最优的超平面。
那么这个损失函数必须符合一些约束条件[根据二分类问题定义出来的]
以下是我问CHATGPT的(逃)
1.所有样本点都需要被正确分类
即
其中,
2.分类器的间隔需要被最大化
即求超平面使得有
1.引入拉格朗日对偶性
实际上,对于
所以我们的目标转化为了求
约束条件为
求最大是困难的,因此我们考虑转换为求最小问题。
即我们求
[至于为什么用后面而不是直接使用倒数,我认为是为了引入拉格朗日对偶性,并且你可以方便地转换为一个凸二次规划问题,用现成的算法简单求解。]
这里就贴一个别人的看法
1 | 那什么是拉格朗日对偶性呢?简单来讲,通过给每一个约束条件加上一个拉格朗日乘子(Lagrange multiplier),定义拉格朗日函数(通过拉格朗日函数将约束条件融合到目标函数里去,从而只用一个函数表达式便能清楚的表达出我们的问题) |
更具体的解释可以在我给出的链接中找到,这里不做赘述。
[简单来说,函数距离,即括号当中的公式,为负类会导致无穷大,而正类不会]
根据以上的说明,我们引入拉格朗日乘子后,将约束条件融入了函数当中,即用一个函数就能表达我们给出的约束。
现在我们的目标函数,即: $\min{w,b}\max{a_i>=0}\mathcal L(w,b,a)$
我们来解释这个函数,首先
其次,
最后
2.化简目标函数
下式来源有两种说法
1.根据 K.K.T. 条件中的梯度向量平行条件
2.首先固定
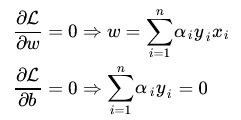
引用上述结论,带入
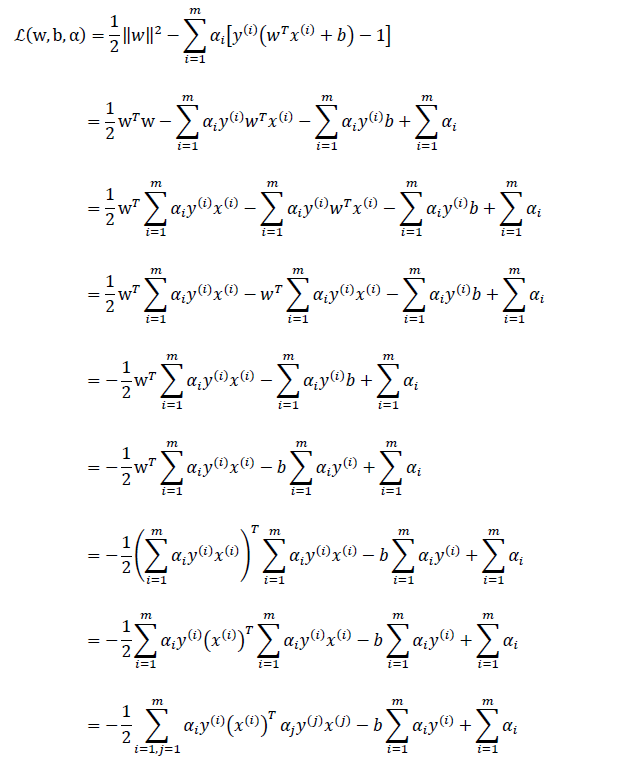
最后有:
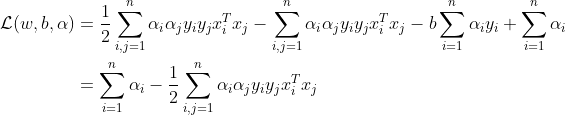
最后得到只剩下
显然,根据
我们可以求出
怎么求解
Ⅱ.经验风险最小化
引入
相较于上一种方法,这种方法似乎实用主义了不少。
在机器学习领域,一般的做法是经验风险最小化 (empirical risk minimization,ERM),即构建假设函数(Hypothesis)为输入输出间的映射,然后采用损失函数来衡量模型的优劣。求得使损失最小化的模型即为最优的假设函数,采用不同的损失函数也会得到不同的机器学习算法。SVM采用的就是Hinge Loss,用于“最大间隔(max-margin)”分类。
就是引入hinge loss作为损失函数即可。这一块比较直觉,我暂时没有更多的严格数学解释。
通过对李宏毅老师的学习,我们得到了如下一些损失函数来做比对
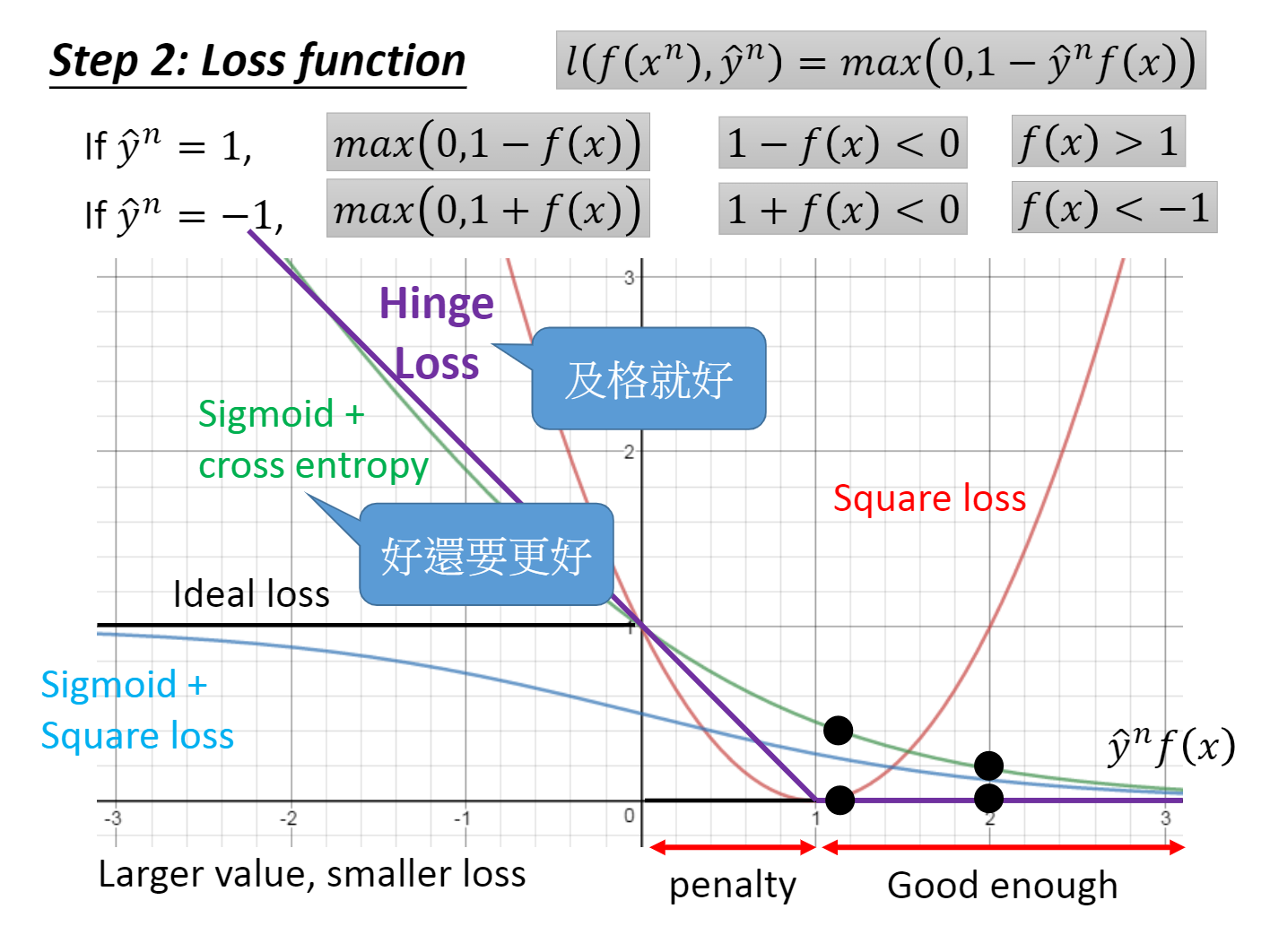
你可以只有的选取损失函数,当然存在不合理的损失函数,例如二次函数,因为你某个时刻会在结果应该越好时却导致损失函数越大。
hinge loss function
对于hinge loss function,用数学语言表达: $l(\hat y^{(n)},f(x{}^{n})=max(0,1-\hat y^{(n)}*f(x{}^{n}))$
虽然这个函数在分界点不可微,但是我们可以特判,特别的认为它在这一点为0?[据李宏毅老师是怎么说的]
因此对于SVM的所有数据,可以得到LOSS FNCTION为 $L(\hat y^{(n)},f(x{i}^{n}))=\sum{i=1}^{n} l(\hat y^{(n)},f(x_{i}^{n}))$
[你当然可以考虑加入正则项,这里我们不做考虑]
于是将

为了方便起见,我们记求导后的结果为
然后我们就可以方便的梯度下降了。
算法做法[3]
根据以上的知识我们以及可以使用SVM解决线性的二分类问题。
到了非线性可分似乎就不起作用了,为了解决这个问题,我们引入核函数这一概念。
简单来说,就是通过将数据升维从而可以在某一维度上线性可分。
升维的方式有很多种,如果你升维后再进行计算,会导致你的参数数量以指数级的速度增长。如果使用核函数的方法进行升维,你应该多花费
就像在下图,你爆算

核函数
详细的内容你可以在我给出的链接清晰的了解,这里不再赘述.
并且李宏毅老师给出了详细的说明解释.
简单来说,你将升维后进行乘积转化为了乘积之后再开方.[当然,你的核函数可以多样化,不一定遵循这个条件]
参考资料
1.支持向量机通俗导论(理解SVM的三层境界)_v_JULY_v的博客-CSDN博客
2.ML-NLP/Machine Learning/4. SVM at master · NLP-LOVE/ML-NLP (github.com)
3.机器学习方法—损失函数(三):Hinge Loss - 知乎 (zhihu.com)
4.SVM Kernel学习笔记_天外有菌的博客-CSDN博客
5.SVM——(二)线性可分之目标函数推导方法2svm线性可分的目标函数是( )。空字符(公众号:月来客栈)的博客-CSDN博客

快晴
スーパーヒーローになってみたい