集成学习
集成学习,字面意思,如果你的方法很烂但又不想花大功夫,我们可以将一堆模型糅合,得到一个较优的模型。当然,我们不能随意糅合,我们必须要有一定的规范标准,这就是集成学习。
严格地说,集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的 泛化性能.这对“弱学习器”(weak learner)尤为明显,因此集成学习的很多理 论研究都是针对弱学习器进行的,而基学习器有时也被直接称为弱学习器.但 需注意的是,虽然从理论上来说使用弱学习器集成足以获得好的性能,但在实践中出于种种考虑,例如希望使用较少的个体学习器,或是重用关于常见学习器的一些经验等,人们往往会使用比较强的学习器。
一般来说,集成学习,有bagging,boosting两类方法。个体学习器间存在强依赖关系、必须串行生成的序列化方法,以及个体学习器 间不存在强依赖关系、可同时生成的并行化方法;前者的代表是Boosting,后 者的代表是Bagging和 “随机森林” (Random Forest)。
bagging
其算法可以简单理解为如下:
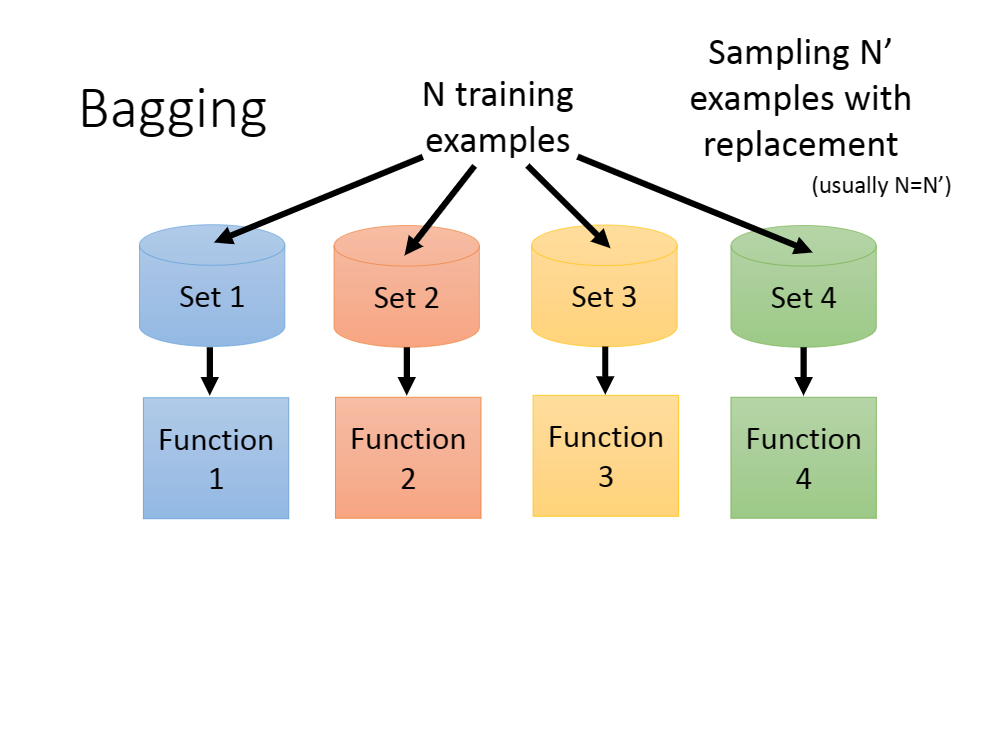
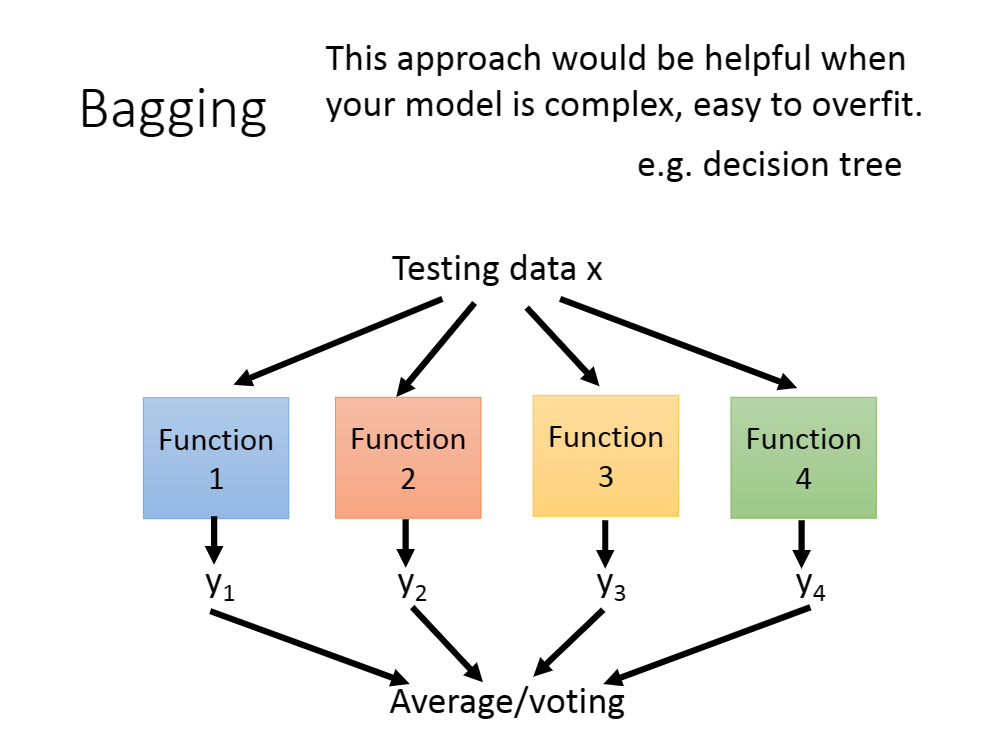
简单来说,我们可以将所有数据集分为$
决策树+随机森林
决策树
决策树算法非常简单,这里不做赘述。简单来说,就是对于任意一个非叶子节点判别然后分为两类,其子节点[非根节点]对于继续迭代直到根节点。
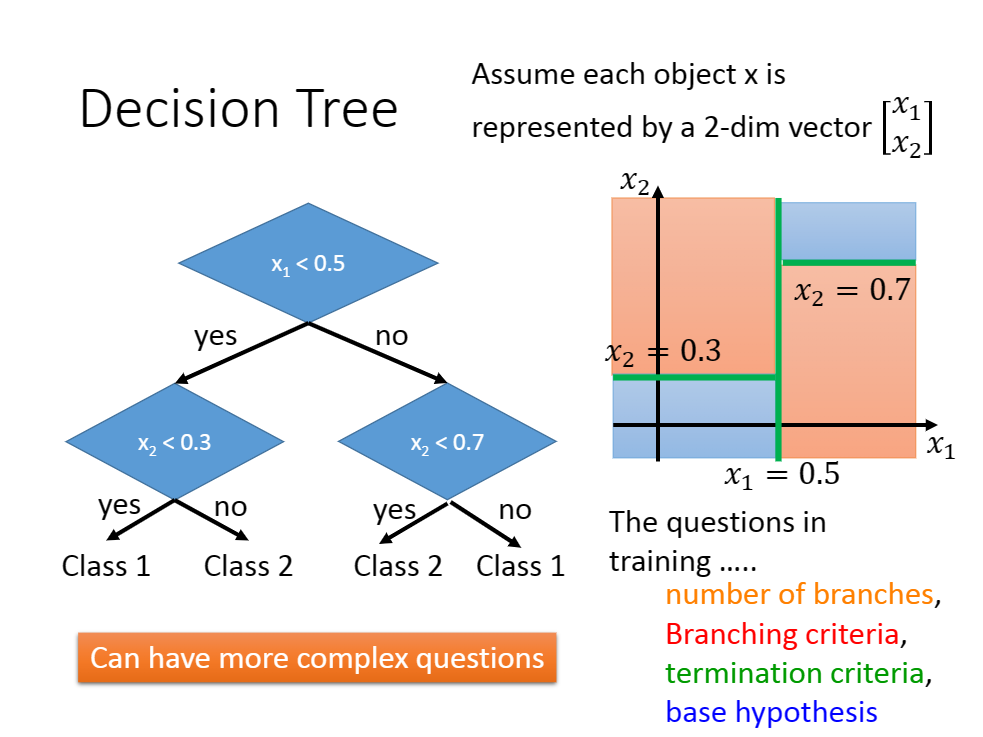
决策树算法只要你想,就能够做到100%的训练集准确率。所以也很容易过拟合。
随机森林
可以将随机森林理解为提升决策树算法的泛化能力做出的改进。运用了bagging的思想在决策树上面。
我们假设划分了$
也就如图:

利用随机森林,我们得到ミク的预测算法集会更加的平滑。

boosting
注意:The classifiers are learned sequentially.
adaboosting
当你的
推广到一般情况,你需要依照次序构造 $ f1

简单做法,我们强调$fi

具体做法,我们令
故有,$\varepsilon1=\frac{\sum{i=1}^{n}u{1}^{n}\delta(f_1(x^i)!=\hat y^i)}{Z_1}
我们如何计算对于$f2
上面提及,就用
我们强调$fi
f{i+1} d_i d_i$。如下图。
即可。
我们如何计算对于$u{2}^{n}
推导过程如下:


于是
我们将上述结果写入公式当中,有如图:

实际上我们可以使用一个数学公式来简短的表达if—else这样的情形,即
$u{t+1}^{n}=u{t}^{n}*\exp(-\hat y^nft(x{}^{n})a_t)
即如下图:

伪代码如下:
[公式写法上会略有不同,不影响]
adaboosting相关数学证明
1.为什么引入越来越多的学习器是可行的。
如下图:
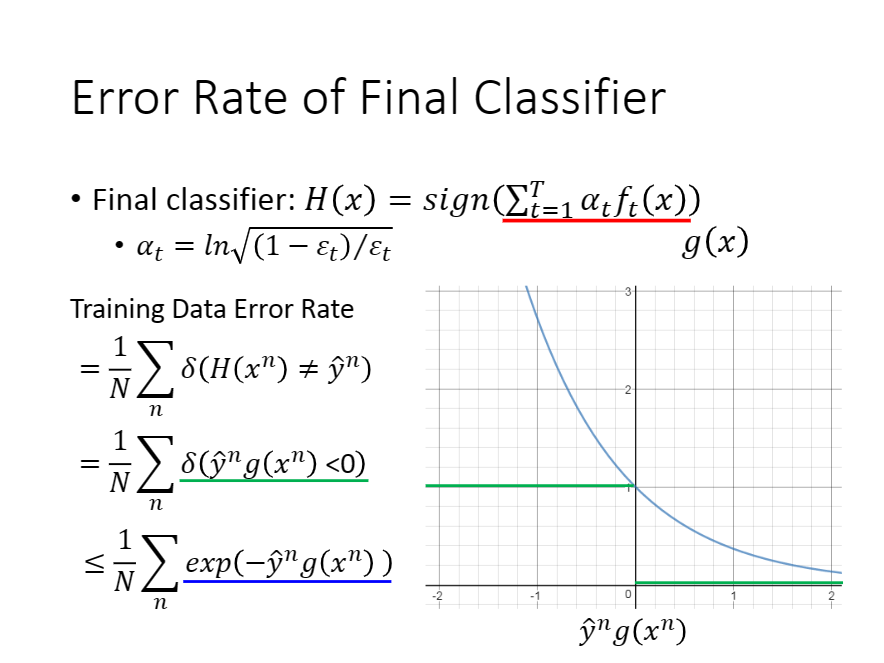
图上的图表中给出
易知,
故$\sum{i=1}^{n}\delta(H(x^i)!=\hat y^i)<=$$\sum{i=1}^{n}\exp(-\hat y^ig(x^i))$
由此得到上式。
我们继续推导,有下图:


最后我们得到$Z{T+1}=N\prod{t=1}^{T}2\sqrt{\epsilon_t(1-\epsilon_t)}$。
显然对于任何
我们能使
以上证明只有在各个基学习器之间相互独立才能成立。
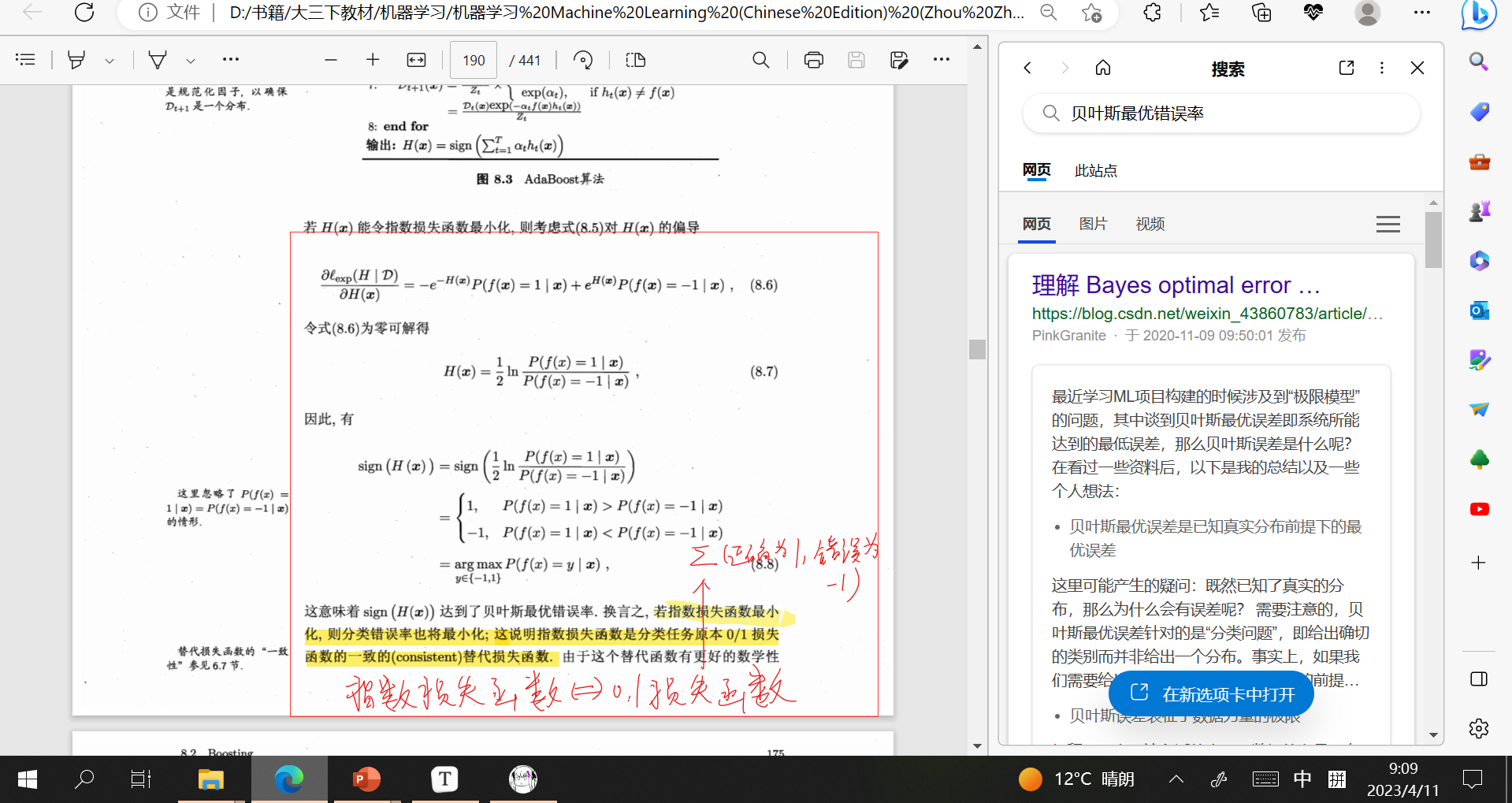
2.西瓜书上给出
但是
推导如下[突然引入贝叶斯最优错误率有点猝不及防,看了一下相关证明,非常的数理统计()]
可以考虑看Zhang, 2004,英语苦手这里
更加一般的boosting
实际上我们使用梯度下降套入boosting后得到的结果和adaboosting一致。李宏毅老师的ppt里有,这里不做赘述。
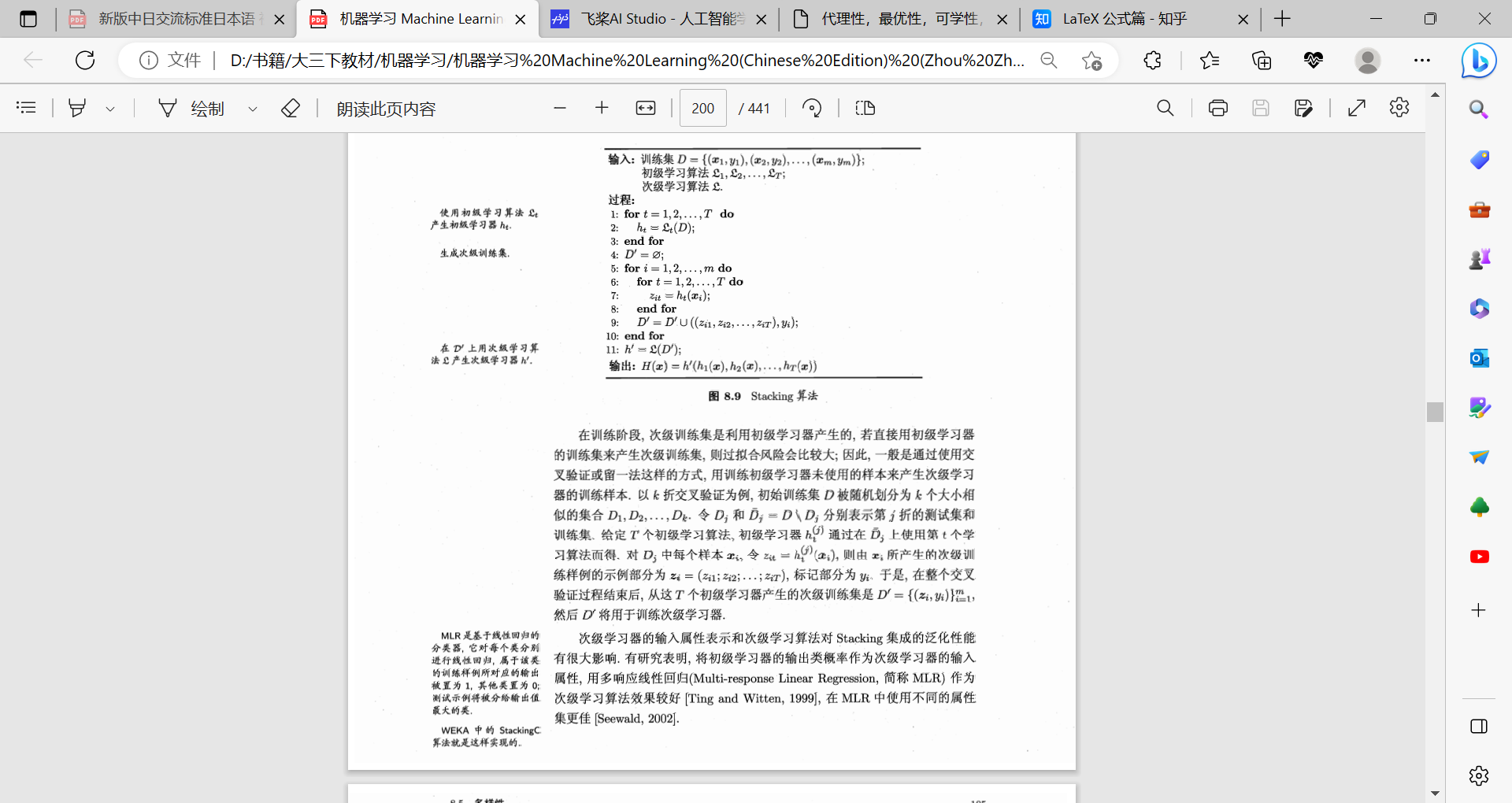
stacking
假设我们只有初级
根据我们的次级学习器,对初级学习器的输出做预测得到我们的输出。
题外话
K折交叉验证法
在简单的交叉验证过程中,我们已经把原数据划分为训练集、验证集和测试集,但由于并不是所有的数据都参与了模型训练(至少验证集没有),因此就存在数据信息利用不全的弊端;此外,不同的划分结果也会导致模型不同的训练效果。
为了确保泛化误差的稳定性,从而得到理想的模型,我们就需要利用K折验证法,其一般流程如下:
(1) 将数据集分为训练集和测试集,测试集放在一边。
(2) 将训练集分为 k 份,每次使用 k 份中的1 份作为验证集,其他全部作为训练集。
(3) 通过 k 次训练后,得到了 k 个不同的模型。
(4) 评估 k 个模型的效果,从中挑选效果最好的超参数。
(5) 使用最优的超参数,然后将 k 份数据全部作为训练集重新训练模型,得到最终所需模型,最后再到测试集上测试。
参考资料

快晴
スーパーヒーローになってみたい