深度学习
深度学习引言
杂谈及其相关概念
二十世纪中叶就已经提出神经网络的模型,并且使用感知机算法得到了实现。
但是只停留在单层感知机的地步,因此很多问题,尤其是非线性分类问题无法解决,导致这个方法烂掉了。
到了1980年,多层感知机的提出,感知机算法能够解决非线性的问题了。但是没多久就有人证明:一层感知机就能实现多层感知机的功能。然后这个方法又烂掉了。以至于反向传播算法[当时仍然基于多层感知机]提出时都没有人关心。
最后到了二十一世纪初,RBM的提出,让大家又对类感知机算法提起了兴趣,但是这个算法的名声基本烂掉了,所以大家给他换了一个“深度学习”的名字。
其实笔者在学习完毕后会有一些疑问:
Q:多层神经网络[DNN]和多层感知机有什么区别。
A:就以目前的知识来说,这两者很像,似乎是等价的。
Q:感知机和深度学习的区别是什么。
A:通俗的理解,感知机和深度学习都利用神经网络的模型进行学习。但是深度学习会有更多的trick和变形能够更好地训练复杂的模型。
难度评级
因为神经网络的不可解释性,导致在基础学习基本上没有困难的数学内容,因此本章比较算法,鉴定为:简单。
多层感知机[多层网络]
神经网络引言
神经网络实际上就是在模仿人类的神经系统。因此单层神经网络模型由以下成分构成,[输入,神经元,输出]。
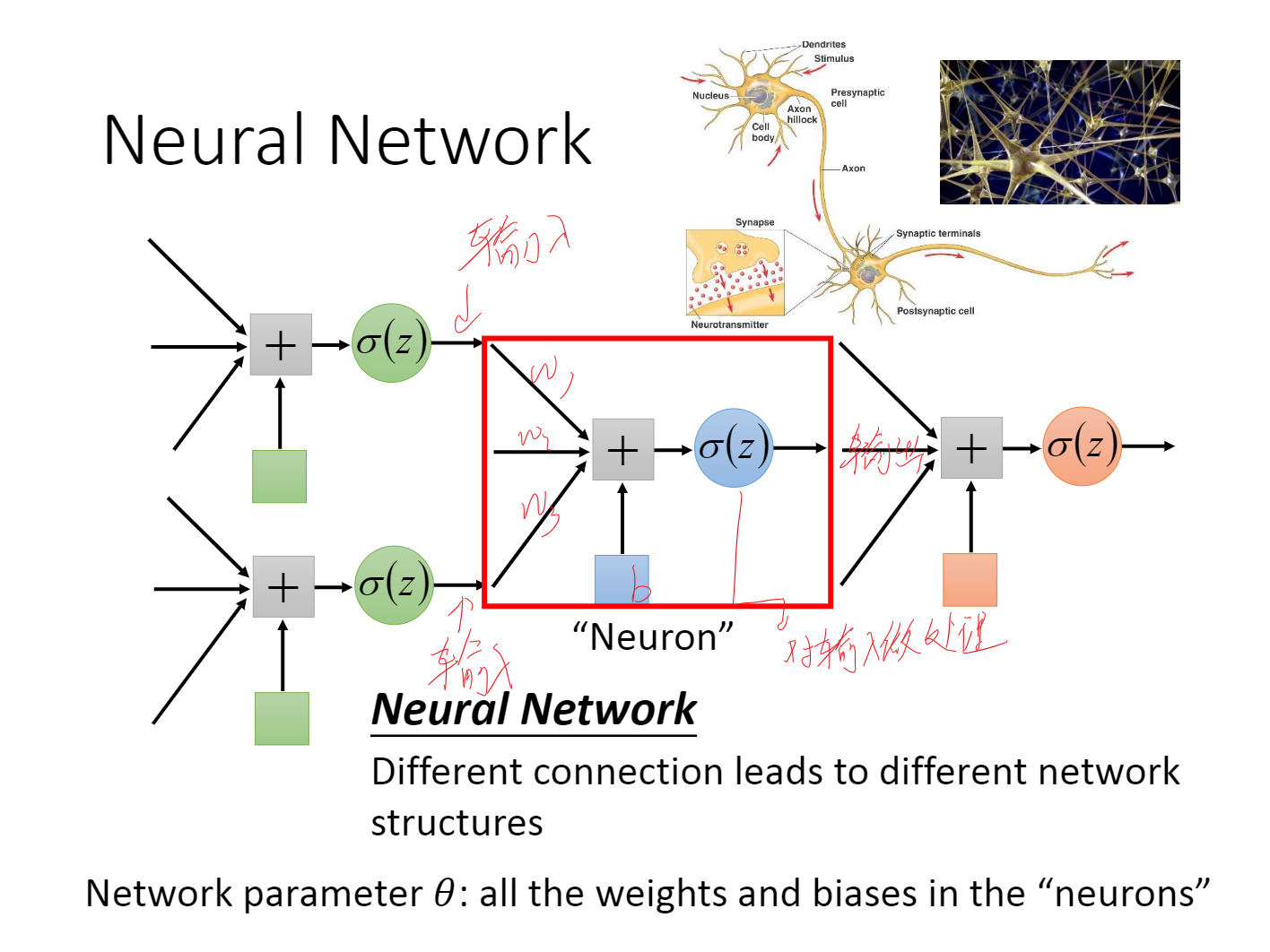
在西瓜书当中,以这样的形态出现[西瓜书将神经元简化画出,实际上一模一样]
对于每一个输入,突触上都要一个权值[w],我们将其整合到[+]时,加上一个bias,最后其输出整合到你定下的激励函数
你当然可以任意地构造你的神经网络的结构,只要对于每一层网络,没有缺少输入,神经元,输出即可。
实际上到这里,朴素神经网络模型就讲完了。
对于大多问题,单层感知机实际上是不能解决大多问题的,因此我们引入多层感知机,一般的我们使用全连接前馈神经网络。
全连接前馈神经网络
一般来说,全连接前馈神经网络的结构如下:
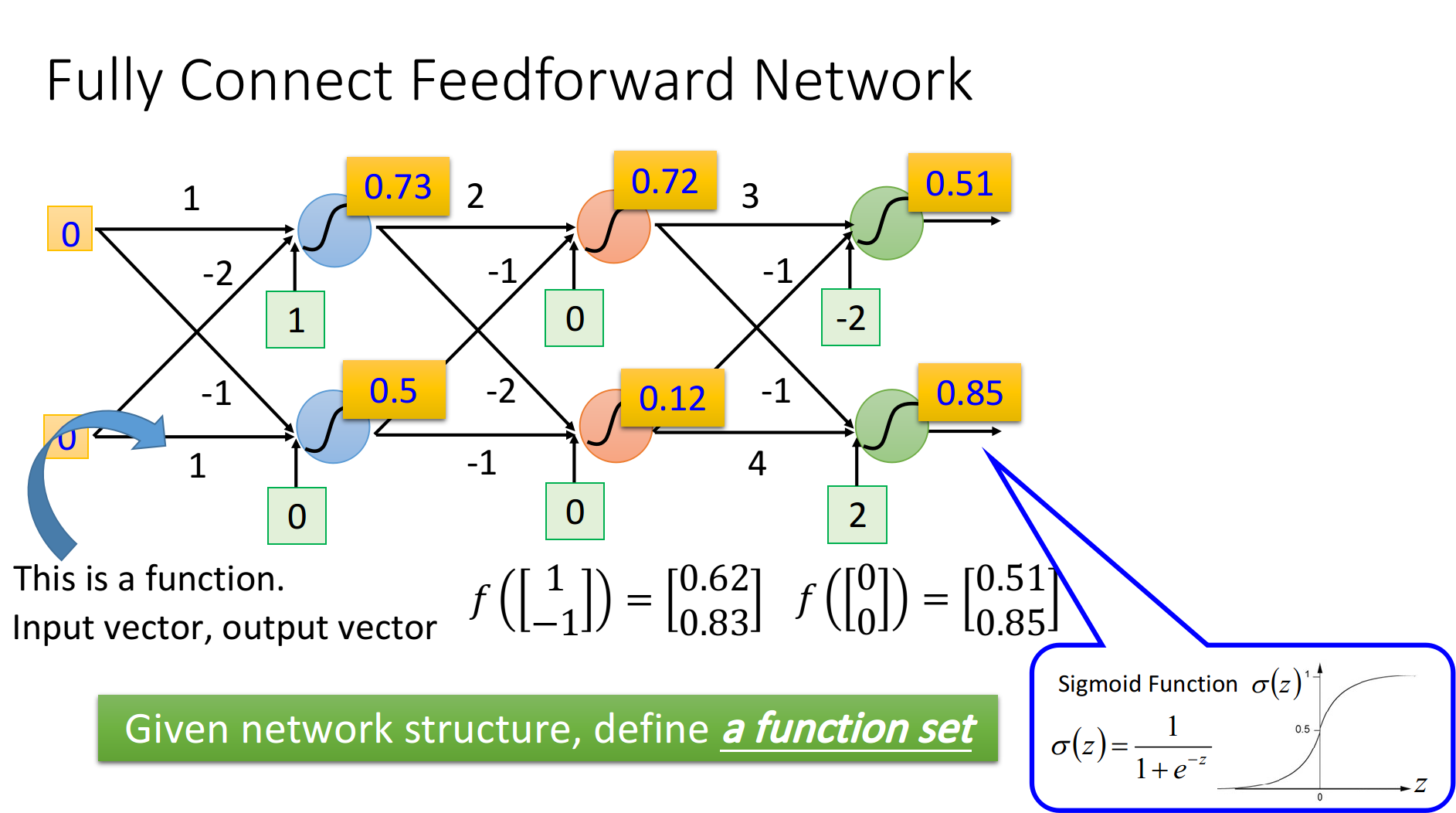
全连接:指前一层的全部输出都与本层的每一个神经元链接。
前馈:指你的信息[一般指输入],是依次向更深层传播的,是单向的。
我们通常将第一层的输入称为输入层[即一堆输入,没有神经元],最后一层称之为输出层[不直为输出的值,为那一层],其余层称之为隐层。
那么全连接前馈神经网络也全部讲完了。
为了深入理解,我们进行实作。
就以上图为例
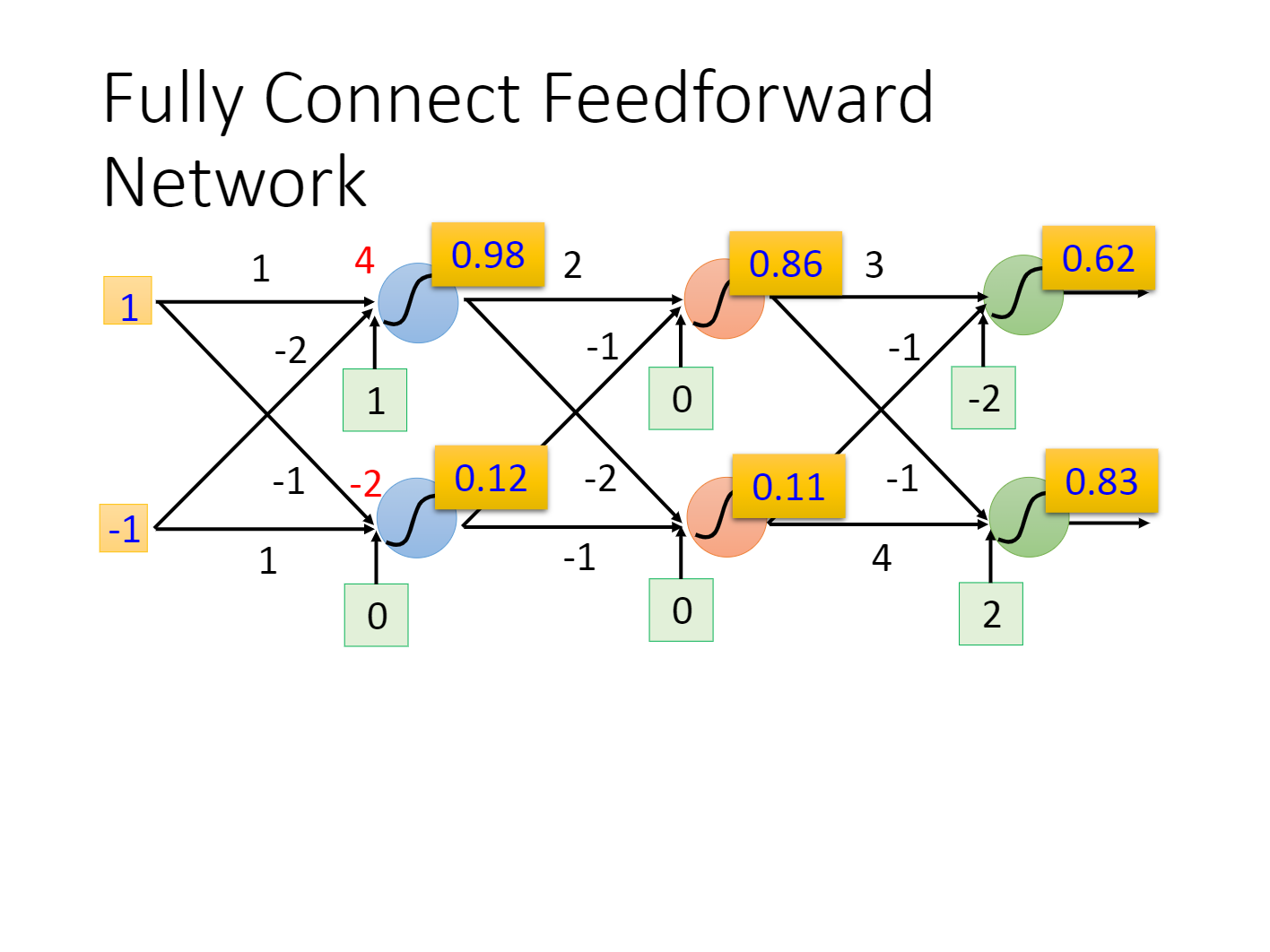
我们的输入是
则对于第二层神经网络,则有$f{21}(input_3,input_4)=\sigma(input_32+input_4(-1))
做法
对于多层感知机,我们只要去构建其结构即可[包括链接方式以及神经元的神经元上的函数],对于神经元突触上的权重,这个是通过学习,模型自己得到的。
那么对于计算机,它学习的具体做法如下。
1.确定你的神经网络结构
2.确定你的损失函数
你当然可以任意选取损失函数例如均方误差或交叉熵,这里我们现在交叉熵。
即:
3.使用好的方法最小化你的损失函数
同样的,我们使用梯度下降可解。
我们可以知道
4.得到一组合适的参数[权重]后结束训练
[误差]反向传播
我们如果进行朴素多层感知机结束后,得到了一个可用的模型。
现在我们想模型当中输入$
如果使用均方误差表示,我们的误差为
我们希望重新训练这个模型使得这个误差尽可能小,有什么方法呢。
这里我们就提出了误差反向传播,反向传播实际上就是gradient descent。
其思想就是将误差分摊到每一个神经元上。
具体做法为如下图:
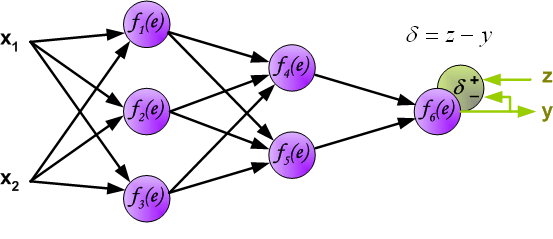
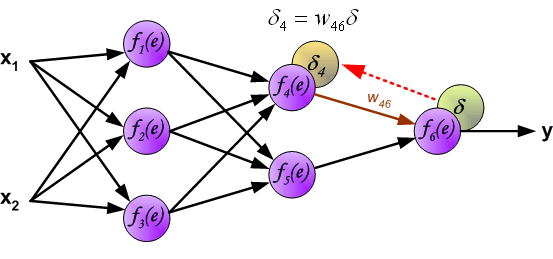
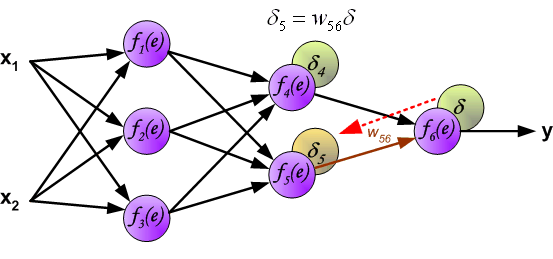
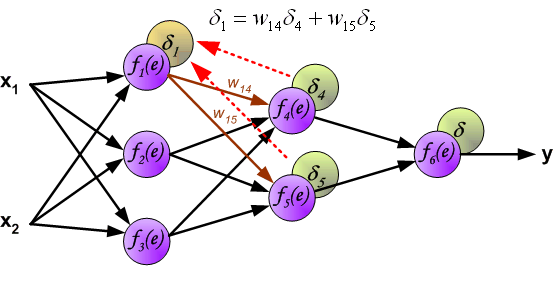
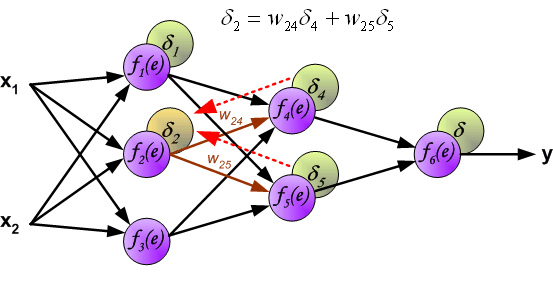
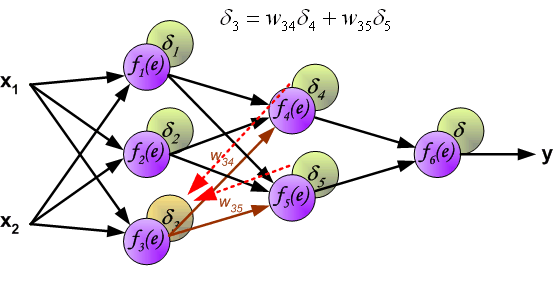
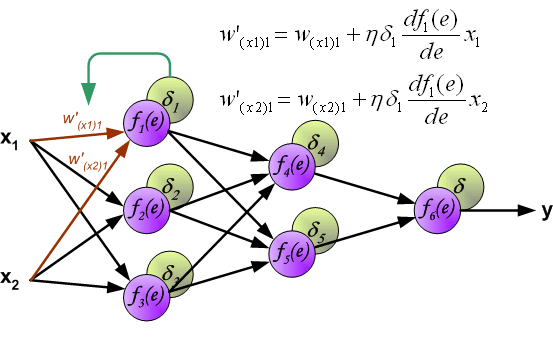

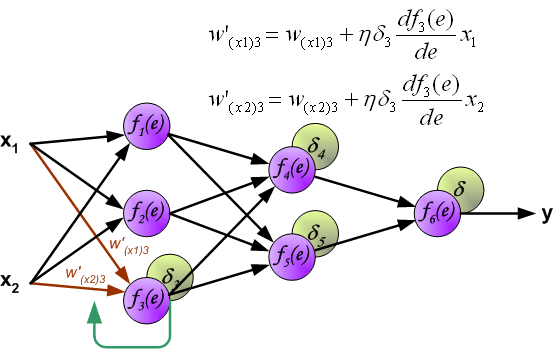
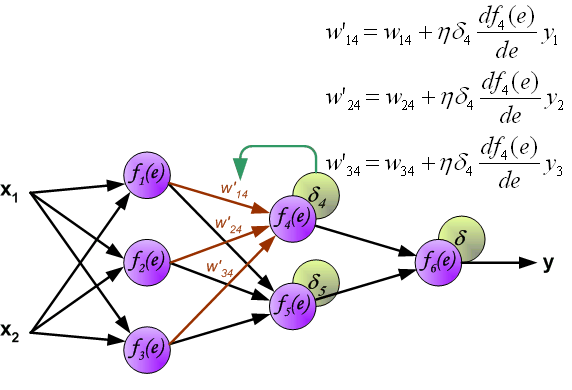
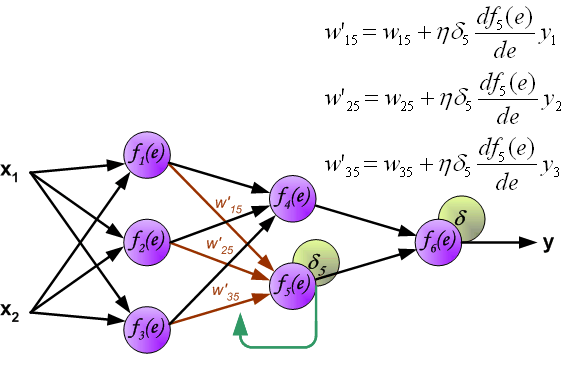
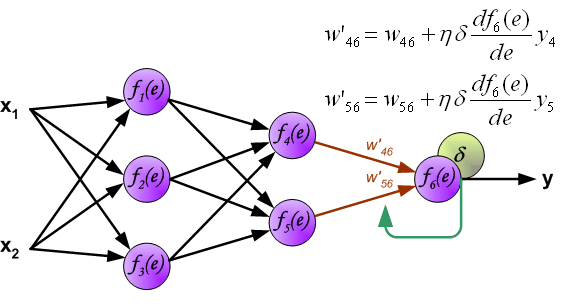
相同地,我们对其他需要更新的参数进行相同的操作即可。
如果我们按照西瓜书上的说法了解释,如下:
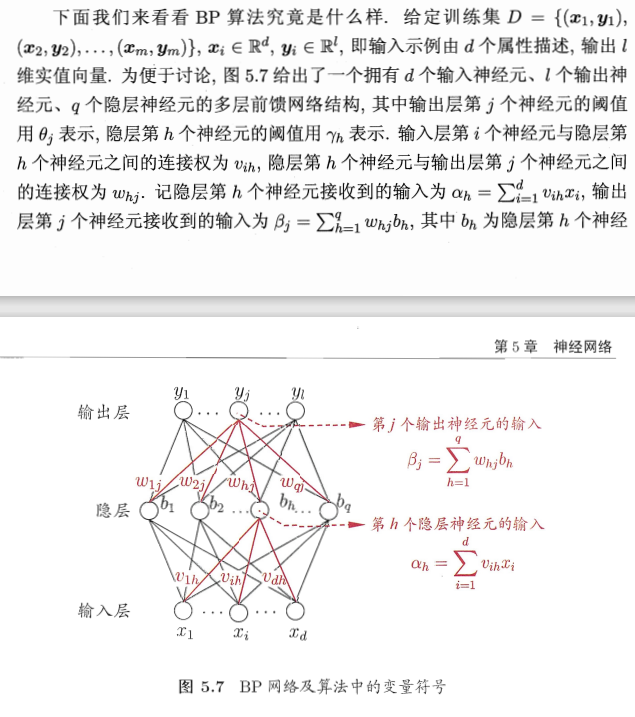



实际上,对于西瓜书上
但是问题是对于输出层
$\sum{j=1}^{l}w{hj}g_j
注意
反向传播因为误差会反向地根据层度加深不断累乘,很可能导致之后的误差发散。因此反向传播一般只适合用于层度较浅的神经网络[2,3层]。
卷积神经网络
引言
注意到,如果朴素的使用全连接前馈神经网络会让你的神经网络极其复杂,你的参数数量会异常地多,让模型的训练是困难的。因此我们提出了卷积神经网络的标准模式来降低你模型的复杂度。
并且根据卷积神经网络的性质,它非常适合用于图像处理,这里不做详细展开。
具体做法
卷积神经网络流程如图下
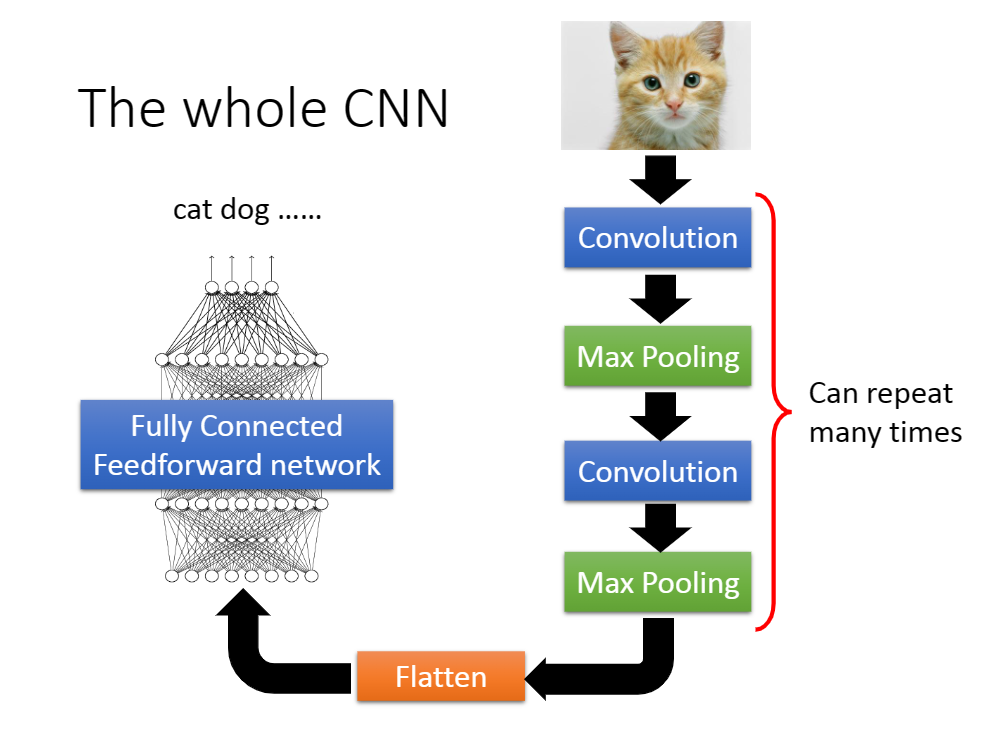
1.卷积
具体卷积是什么笔者不详细介绍,相关资料《信号与系统》,以及简单介绍。
假设我们有卷积核$Q{a*b}
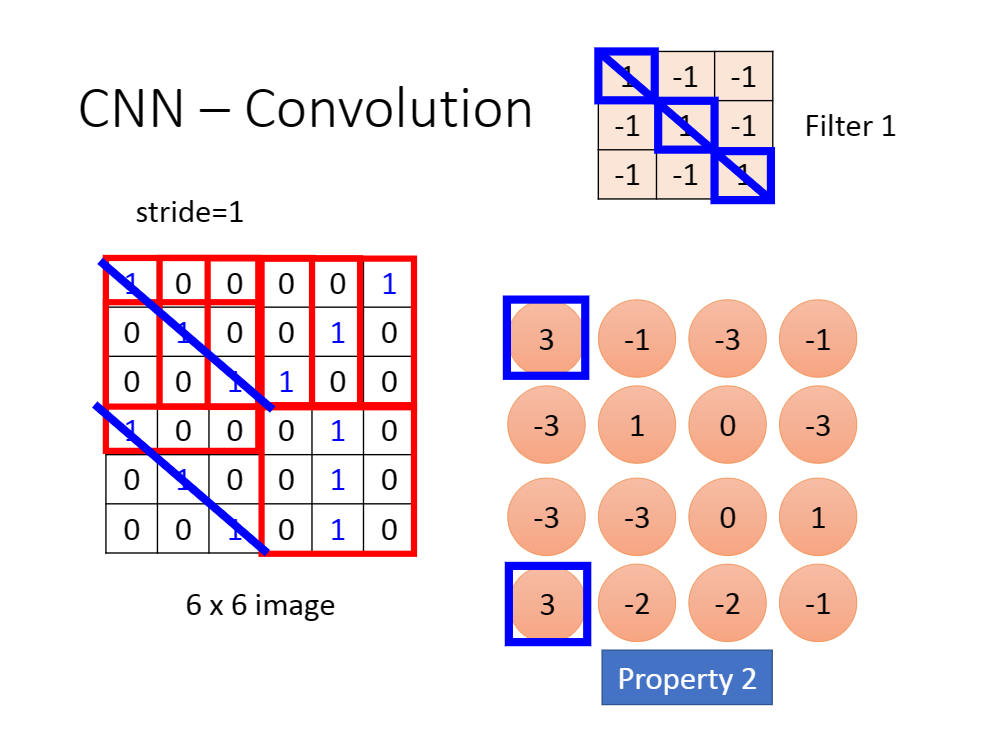
对于每一个卷积核,你可以看做一个滤波器,提取每一个矩阵对于该卷积核的特征到一个值上,最后所有矩阵的特征形成一个新矩阵。
对于不同的卷积核,我们得到不同的输出矩阵。最后我们将这些矩阵叠起来,成为一个三维矩阵。
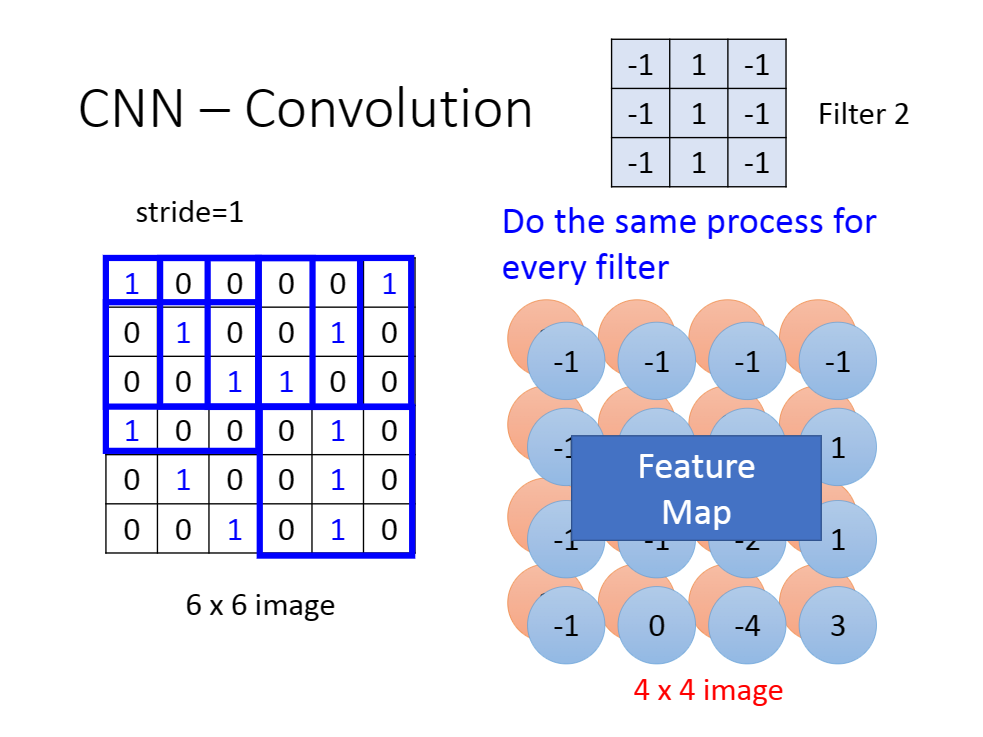
[上图前后各有一个矩阵]
Q1:不是说减少参数吗?这里怎么从原来的6*6个数字变成4*4*2个数字了,按这种趋势,数字的个数不是会越来越多吗?
A1:虽然数字的增加,但是我们使用权值共享的方法,仍可以让我们的参数量变少。
权值共享
假设我们对上面得到的三维矩阵做卷积,我们不需要一个个二维矩阵进行考察,而是直接从三维矩阵顶端考察到底端。
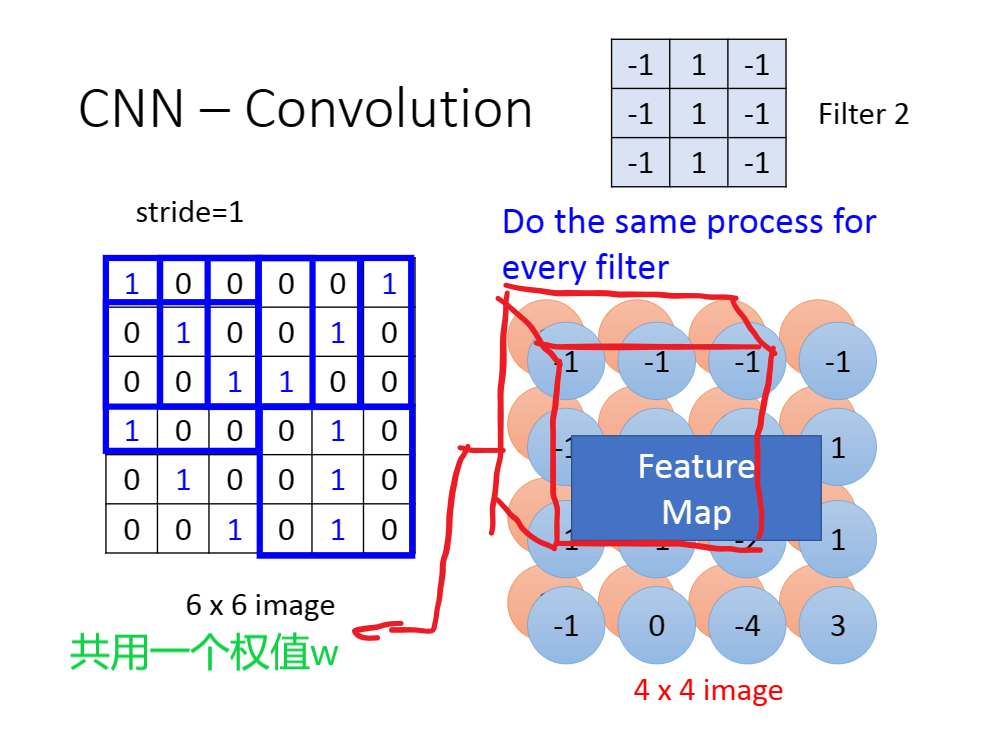
因此我们的参数量
Q2:那么这个卷积和神经网络有什么关系,不就是个预处理吗?
A2:对于卷积,我们可以看做为神经网络。
我们为输入矩阵每一个数字编号,对于卷积核内的参数,我们用不同颜色的连线表示,有下图:
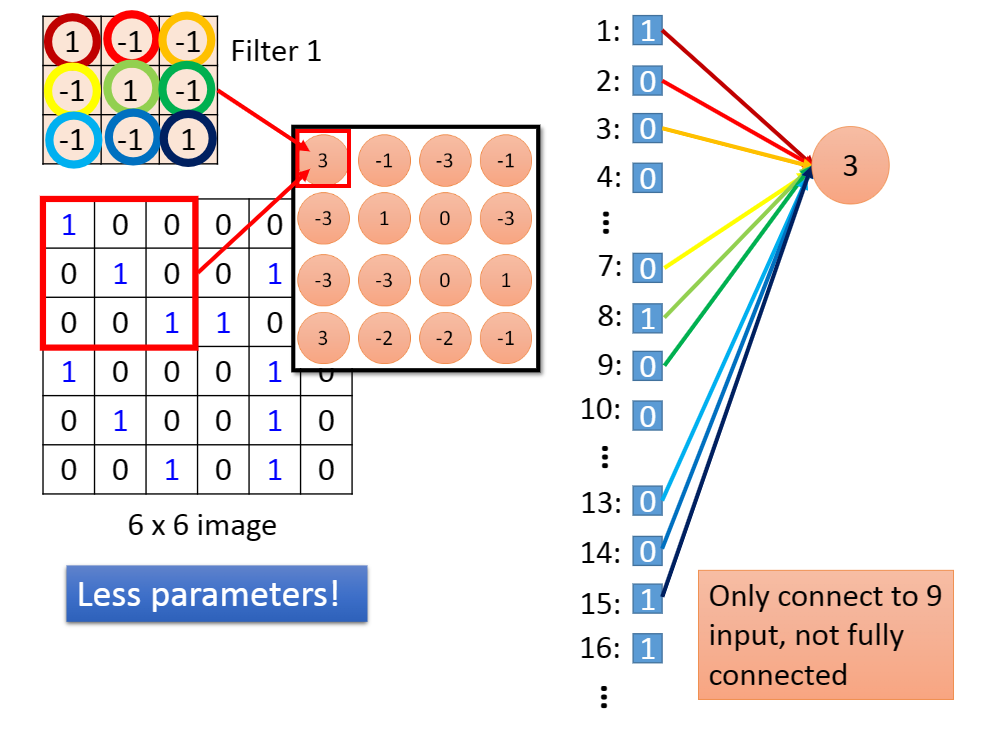
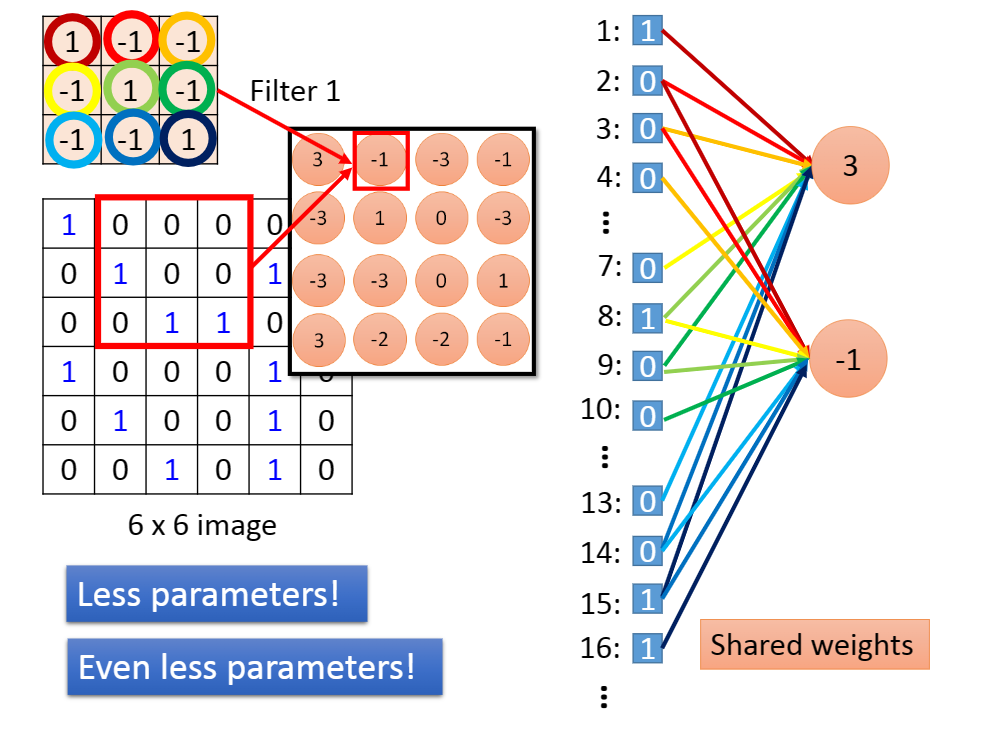
虽然连线多,但是计算并不会复杂,因为它们本身就是一个卷积核的参数而已。
具体怎么在代码当中体现权值共享呢?
怎么让某些neuron的weight值永远都是一样呢?你就用一般的Backpropagation的方法,对每个weight都去算出gradient,再把本来要tight在一起、要share weight的那些weight的gradient平均,然后,让他们update同样值就ok了。
[引用自11_Convolutional Neural Network (gitee.io)]
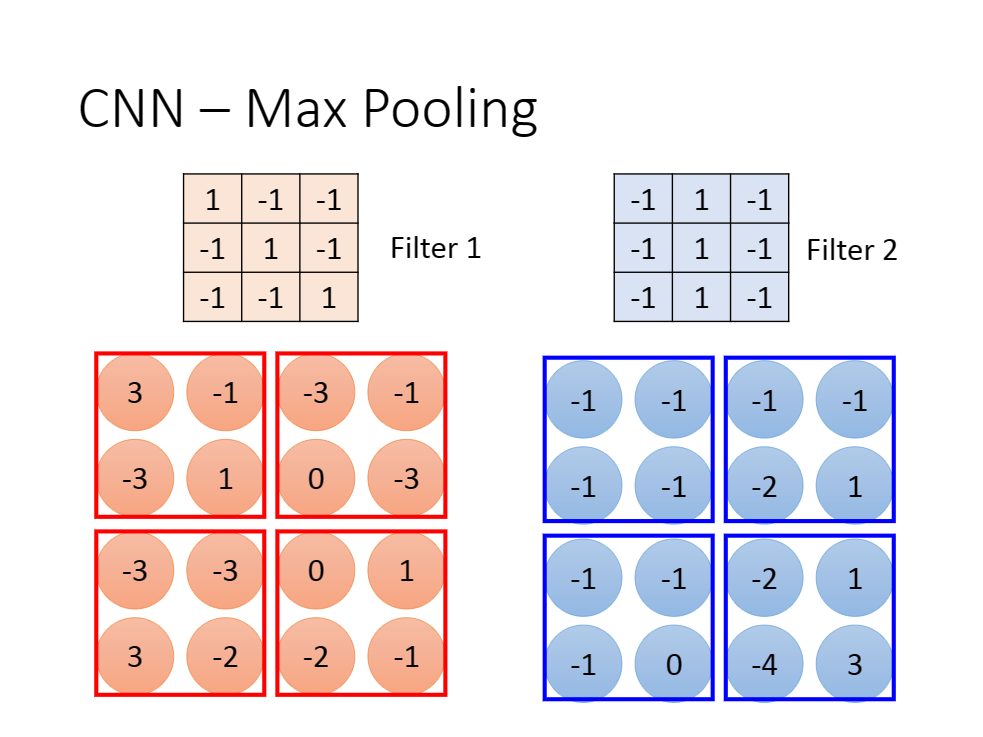
2.池化
简单来说,池化就相当于特征提取。
我们一般采用maxpool的方法。
很简单,就是用矩阵当中的最大值代表矩阵本身即可。
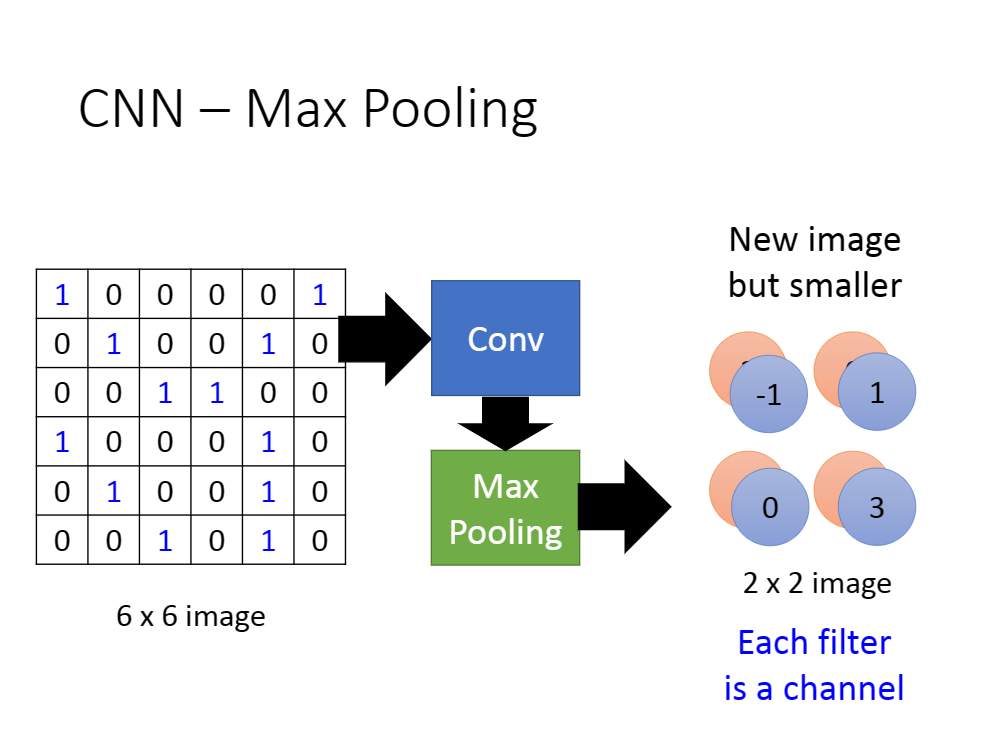
然后,模型不断卷积不断池化,最后得到一个合适的输出[这看你的定义]
有这样一个问题:假设我第一个convolution有25个filter,通过这些filter得到25个feature map,然后repeat的时候第二个convolution也有25个filter,那这样做完,我是不是会得到25^2个feature map?
其实不是这样的,你这边做完一次convolution,得到25个feature map之后再做一次convolution,还是会得到25个feature map,因为convolution在考虑input的时候,是会考虑深度的,它并不是每一个channel分开考虑,而是一次考虑所有的channel,所以,你convolution这边有多少个filter,再次output的时候就会有多少个channel
[引用自11_Convolutional Neural Network (gitee.io)]
我们要考虑输出矩阵[feature map]的深度,假设有
你的数字数量[计算量]很可能是在增加的[具体看你的卷积和池化方式],但是你的参数数量仍是相对较少的。
3.映射[平滑处理]
通俗地说,我们将得到的输出拉直即可。如图:
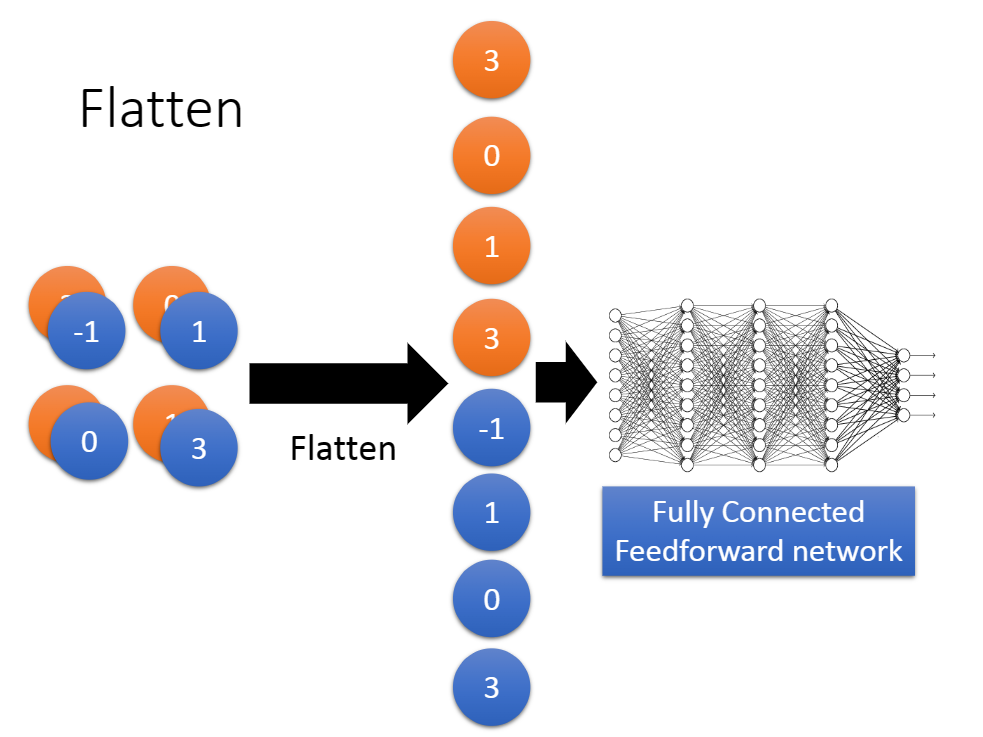
但是平滑处理后的结果要符合你神经网络的输入层要求。
4.神经网络
没什么好说的,随便套一个神经网络就行了,不再赘述。
局限性
我们发现,对于深度学习,其参数的设定似乎是不那么重要的,因为机器可以自己学习。甚至神经网络的结构都可以由机器自己构建。但是产生了”特征工程”这个问题。
你构建filter需要知道你想要的特征如何数学表示,才能构建你的特征模型。这也是困难的,因此深度学习只是把A问题的解决转换到了B问题上。
循环神经网络
暂时先咕着()
参考资料
飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)
飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)
飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)
感知机 | 神经网络 - 腾讯云开发者社区-腾讯云 (tencent.com)
多层感知机(MLP)与神经网络结构 | 深度学习笔记 - 腾讯云开发者社区-腾讯云 (tencent.com)
(2 封私信 / 80 条消息) “深度学习”和“多层神经网络”的区别? - 知乎 (zhihu.com)
Convolutional Neural Network Definition | DeepAI

快晴
スーパーヒーローになってみたい